रॉडिक्स ट्री

कंप्यूटर विज्ञान में, एक मूलांक ट्री एक डेटा संरचना होती है जो मेमोरी अनुकूलन (उपसर्ग ट्री) का प्रतिनिधित्व करती है जिसमें प्रत्येक नोड जो एकमात्र बच्चा होता है, उसके साथ विलय हो जाता है अभिभावक. इसका परिणाम यह होता है कि प्रत्येक आंतरिक नोड के बच्चों की संख्या अधिकतम मूलांक होती है r मूलांक वृक्ष का, जहाँ r एक धनात्मक पूर्णांक और एक घात है x 2, होता है x ≥ 1. नियमित पेड़ों के विपरीत, किनारों को तत्वों के अनुक्रम के साथ-साथ एकल तत्वों के साथ अंकित किया जा सकता है। यह मूलांक ट्री को छोटे सेटों के लिए अधिक कुशल बनाता है (विशेषकर यदि स्ट्रिंग लंबी है) और स्ट्रिंग के सेट के लिए जो लंबे उपसर्ग साझा करते है।
नियमित पेड़ों के विपरीत (जहां संपूर्ण कुंजियों की तुलना उनकी शुरुआत से लेकर असमानता के बिंदु तक की जाती है), प्रत्येक नोड की कुंजी की तुलना चंक-ऑफ-बिट्स द्वारा की जाती है, जहां उस चंक में बिट्स की मात्रा होती है वह नोड मूलांक है r मूलांक त्रि का। कब r 2 है, मूलांक त्रि द्विआधारी है (अर्थात, कुंजी के उस नोड के 1-बिट भाग की तुलना करें), जो त्रि गहराई को अधिकतम करने की कीमत पर विरलता को कम करता है - अर्थात, कुंजी में नॉनडाइवर्जिंग बिट-स्ट्रिंग्स के संयोजन को अधिकतम करता है। कब r ≥ 4, 2 की घात है, तो मूलांक त्रि एक है r-एरी ट्राई, जो संभावित विरलता की कीमत पर मूलांक ट्राई की गहराई को कम करता है।
एक अनुकूलन के रूप में, किनारे के अंकित को एक स्ट्रिंग में दो पॉइंटर्स का उपयोग करके स्थिर आकार में संग्रहीत किया जा सकता है (पहले और आखिरी तत्वों के लिए)।[1] ध्यान दें कि यद्यपि इस आलेख के उदाहरण स्ट्रिंग्स को वर्णों के अनुक्रम के रूप में दिखाते है, स्ट्रिंग तत्वों के प्रकार को मनमाने ढंग से चुना जा सकता है; उदाहरण के लिए, मल्टीबाइट चरित्र एन्कोडिंग या यूनिकोड का उपयोग करते समय स्ट्रिंग प्रतिनिधित्व के बिट या बाइट के रूप में।
अनुप्रयोग
मूलांक ट्री कुंजी के साथ सहयोगी सरणी बनाने के लिए उपयोगी होते है जिन्हें स्ट्रिंग के रूप में व्यक्त किया जा सकता है। वे इंटरनेट प्रोटोकॉल मार्ग के क्षेत्र में विशेष अनुप्रयोग पाते है,[2][3][4] जहां कुछ अपवादों के साथ मूल्यों की बड़ी श्रृंखला को सम्मलित करने की क्षमता विशेष रूप से आईपी पते के पदानुक्रमित संगठन के लिए उपयुक्त है।[5] इनका उपयोग सूचना पुनर्प्राप्ति में पाठ दस्तावेज़ों की उलटी अनुक्रमणिका के लिए भी किया जाता है।
संचालन
मूलांक ट्री सम्मिलन, विलोपन और खोज कार्यों का समर्थन करते है। संग्रहीत डेटा की मात्रा को कम करने का प्रयास करते समय सम्मिलन ट्राई में एक नई स्ट्रिंग जोड़ता है। विलोपन ट्राई से एक स्ट्रिंग को हटा देता है। खोज कार्यों में त्रुटिहीन लुकअप, पूर्ववर्ती ढूंढना, उत्तराधिकारी ढूंढना और उपसर्ग के साथ सभी स्ट्रिंग ढूंढना सम्मलित है (लेकिन आवश्यक नहीं कि यह इन्हीं तक सीमित हो)। ये सभी संचालन O(k) है जहां k सेट में सभी स्ट्रिंग्स की अधिकतम लंबाई है, जहां लंबाई मूलांक ट्राइ के मूलांक के बराबर बिट्स की मात्रा में मापी जाती है।
लुकअप
 लुकअप संचालन यह निर्धारित करता है कि किसी ट्राई में कोई स्ट्रिंग उपस्थित है या नहीं। अधिकांश संचालन अपने विशिष्ट कार्यों को संभालने के लिए इस दृष्टिकोण को किसी तरह से संशोधित करते है। उदाहरण के लिए, वह नोड जहां एक स्ट्रिंग समाप्त होती है, महत्वपूर्ण हो सकता है। यह संचालन कोशिशों के समान है, अतिरिक्त इसके कि कुछ किनारे कई तत्वों का उपभोग करते है।
लुकअप संचालन यह निर्धारित करता है कि किसी ट्राई में कोई स्ट्रिंग उपस्थित है या नहीं। अधिकांश संचालन अपने विशिष्ट कार्यों को संभालने के लिए इस दृष्टिकोण को किसी तरह से संशोधित करते है। उदाहरण के लिए, वह नोड जहां एक स्ट्रिंग समाप्त होती है, महत्वपूर्ण हो सकता है। यह संचालन कोशिशों के समान है, अतिरिक्त इसके कि कुछ किनारे कई तत्वों का उपभोग करते है।
निम्नलिखित छद्म कोड मानता है कि ये विधियाँ और सदस्य उपस्थित है।
किनारा
- नोड लक्ष्यनोड
- स्ट्रिंग अंकित
नोड
- किनारों की सारणी
- फ़ंक्शन लीफ () है
function lookup(string x)
{
// Begin at the root with no elements found
Node traverseNode := root;
int elementsFound := 0;
// Traverse until a leaf is found or it is not possible to continue
while (traverseNode != null && !traverseNode.isLeaf() && elementsFound < x.length)
{
// Get the next edge to explore based on the elements not yet found in x
Edge nextEdge := select edge from traverseNode.edges where edge.label is a prefix of x.suffix(elementsFound)
// x.suffix(elementsFound) returns the last (x.length - elementsFound) elements of x
// Was an edge found?
if (nextEdge != null)
{
// Set the next node to explore
traverseNode := nextEdge.targetNode;
// Increment elements found based on the label stored at the edge
elementsFound += nextEdge.label.length;
}
else
{
// Terminate loop
traverseNode := null;
}
}
// A match is found if we arrive at a leaf node and have used up exactly x.length elements
return (traverseNode != null && traverseNode.isLeaf() && elementsFound == x.length);
}
निवेशन
एक स्ट्रिंग डालने के लिए, हम पेड़ को तब तक खोजते है जब तक हम आगे प्रगति नहीं कर पाते। इस बिंदु पर हम या तो इनपुट स्ट्रिंग में सभी शेष तत्वों के साथ अंकित किया गया एक नया आउटगोइंग एज जोड़ते है, या यदि पहले से ही शेष इनपुट स्ट्रिंग के साथ एक उपसर्ग साझा करने वाला आउटगोइंग एज है, तो हम इसे दो किनारों में विभाजित करते है (पहला आम के साथ अंकित किया गया है) उपसर्ग) और आगे बढ़ें। यह विभाजन चरण यह सुनिश्चित करता है कि किसी भी नोड में संभावित स्ट्रिंग तत्वों की तुलना में अधिक बच्चे नहीं है।
सम्मिलन के कई स्थिति नीचे दिखाए गए है, चूँकि और भी उपस्थित हो सकते है। ध्यान दें कि r केवल मूल का प्रतिनिधित्व करता है। यह माना जाता है कि जहां आवश्यक हो वहां स्ट्रिंग्स को समाप्त करने के लिए किनारों को खाली स्ट्रिंग्स के साथ अंकित किया जा सकता है और रूट में कोई आने वाला किनारा नहीं है। (खाली-स्ट्रिंग किनारों का उपयोग करते समय ऊपर वर्णित लुकअप एल्गोरिदम काम नहीं करेगा।)
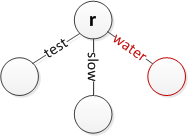
जड़ में 'पानी' डालें
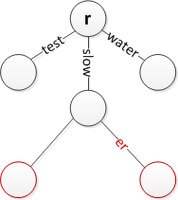
'धीमा' रखते हुए 'धीमा' डालें

'टेस्ट' डालें जो 'टेस्टर' का उपसर्ग है

'टेस्ट' को विभाजित करते समय और एक नया एज लेबल 'सेंट' बनाते समय 'टीम' डालें
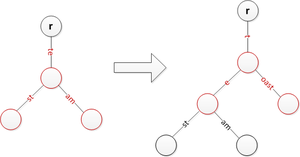
'ते' को विभाजित करते हुए और पिछले तारों को एक स्तर नीचे ले जाते हुए 'टोस्ट' डालें





विलोपन
किसी पेड़ से एक स्ट्रिंग x को हटाने के लिए, हम पहले x का प्रतिनिधित्व करने वाले पत्ते का पता लगाते है। फिर, यह मानते हुए कि x उपस्थित है, हम संबंधित लीफ नोड को हटा देते है। यदि हमारे लीफ नोड के माता-पिता के पास केवल एक अन्य बच्चा है, तो उस बच्चे का आने वाला अंकित माता-पिता के आने वाले अंकित में जोड़ा जाता है और बच्चे को हटा दिया जाता है।
अतिरिक्त संचालन
- सामान्य उपसर्ग वाली सभी स्ट्रिंग्स ढूंढें: समान उपसर्ग से प्रारंभ होने वाली स्ट्रिंग्स की एक सरणी लौटाता है।
- पूर्ववर्ती खोजें: लेक्सिकोग्राफ़िक क्रम के अनुसार, किसी दिए गए स्ट्रिंग से कम सबसे बड़ी स्ट्रिंग का पता लगाता है।
- उत्तराधिकारी खोजें: लेक्सिकोग्राफ़िक क्रम के अनुसार, दी गई स्ट्रिंग से बड़ी सबसे छोटी स्ट्रिंग का पता लगाता है।
इतिहास
डेटास्ट्रक्चर का आविष्कार 1968 में डोनाल्ड आर. मॉरिसन द्वारा किया गया था,[6] यह मुख्य रूप से किसके साथ जुड़ा हुआ है, और गर्नोट ग्वेहेनबर्गर द्वारा।[7] डोनाल्ड नुथ, कंप्यूटर प्रोग्रामिंग की कला के खंड III में पृष्ठ 498-500, इन्हें पेट्रीसिया के पेड़ कहते है, संभवतः मॉरिसन के पेपर के शीर्षक में संक्षिप्त नाम के बाद: पेट्रीसिया - अल्फ़ान्यूमेरिक में कोडित सूचना पुनर्प्राप्त करने के लिए व्यावहारिक एल्गोरिदम। आज, पेट्रीसिया कोशिशों को मूलांक 2 के बराबर मूलांक वाले पेड़ों के रूप में देखा जाता है, जिसका अर्थ है कि कुंजी के प्रत्येक बिट की तुलना व्यक्तिगत रूप से की जाती है और प्रत्येक नोड दो-तरफा (अर्थात, बाएं बनाम दाएं) शाखा है।
अन्य डेटा संरचनाओं की तुलना
(निम्नलिखित तुलनाओं में, यह माना जाता है कि कुंजियाँ k लंबाई की है और डेटा संरचना में n सदस्य है।)
संतुलित पेड़ों के विपरीत, मूलांक पेड़ ओ (लॉग एन) के अतिरिक्त ओ (के) समय में लुकअप, सम्मिलन और विलोपन की अनुमति देते है। यह एक लाभ की तरह प्रतीत नहीं होता है, क्योंकि सामान्यतः k ≥ log n होता है, लेकिन एक संतुलित पेड़ में हर तुलना एक स्ट्रिंग तुलना होती है जिसके लिए O(k) सबसे खराब स्थिति वाले समय की आवश्यकता होती है, जिनमें से कई लंबे सामान्य उपसर्गों के कारण अभ्यास में धीमे होते है (में) वह स्थिति जहां तुलना स्ट्रिंग की शुरुआत में प्रारंभ होती है)। एक प्रयास में, सभी तुलनाओं के लिए निरंतर समय की आवश्यकता होती है, लेकिन लंबाई m की एक स्ट्रिंग को देखने के लिए m तुलना की आवश्यकता होती है। मूलांक ट्री इन संचालनों को कम तुलनाओं के साथ कर सकते है, और बहुत कम नोड्स की आवश्यकता होती है।
चूंकि, मूलांक ट्री कोशिशों के नुकसान को भी साझा करते है: चूंकि उन्हें केवल तत्वों की स्ट्रिंग या स्ट्रिंग के लिए कुशलतापूर्वक प्रतिवर्ती मैपिंग वाले तत्वों पर ही लागू किया जा सकता है, इसलिए उनमें संतुलित खोज पेड़ों की पूर्ण व्यापकता का अभाव होता है, जो कुल मिलाकर किसी भी डेटा प्रकार पर लागू होते है। आदेश देना संतुलित खोज पेड़ों के लिए आवश्यक कुल ऑर्डर तैयार करने के लिए स्ट्रिंग्स की प्रतिवर्ती मैपिंग का उपयोग किया जा सकता है। यह भी समस्याग्रस्त हो सकता है यदि डेटा प्रकार केवल इंटरफ़ेस (कंप्यूटर विज्ञान) एक तुलना संचालन है, लेकिन (डी) क्रमांकन संचालन नहीं है।
सामान्यतः कहा जाता है कि हैश तालिकाओं में अपेक्षित O(1) सम्मिलन और विलोपन समय होता है, लेकिन यह केवल तभी सच है जब कुंजी के हैश की गणना को एक निरंतर-समय का संचालन माना जाता है। जब कुंजी की हैशिंग को ध्यान में रखा जाता है, तो हैश तालिकाओं में O(k) सम्मिलन और विलोपन समय की अपेक्षा की जाती है, लेकिन सबसे खराब स्थिति में टकराव को कैसे संभाला जाता है, इसके आधार पर इसमें अधिक समय लग सकता है। मूलांक पेड़ों में सबसे खराब स्थिति O(k) सम्मिलन और विलोपन की है। मूलांक वृक्षों के उत्तराधिकारी/पूर्ववर्ती संचालन भी हैश तालिकाओं द्वारा कार्यान्वित नहीं किए जाते है।
वेरिएंट
मूलांक वृक्षों का एक सामान्य विस्तार नोड्स के दो रंगों, 'काले' और 'सफ़ेद' का उपयोग करता है। यह जांचने के लिए कि क्या दी गई स्ट्रिंग पेड़ में संग्रहीत है, खोज ऊपर से प्रारंभ होती है और इनपुट स्ट्रिंग के किनारों का अनुसरण करती है जब तक कि आगे कोई प्रगति न हो सके। यदि खोज स्ट्रिंग ख़त्म हो गई है और अंतिम नोड एक काला नोड है, तो खोज विफल हो गई है; यदि यह सफेद है, तो खोज सफल हो गई है। यह हमें सफेद नोड्स का उपयोग करके पेड़ में एक सामान्य उपसर्ग के साथ स्ट्रिंग की एक बड़ी श्रृंखला जोड़ने में सक्षम बनाता है, फिर काले नोड्स का उपयोग करके उन्हें अंतरिक्ष-कुशल विधि से अपवादों के एक छोटे सेट को हटा देता है।
'HAT-trie' मूलांक ट्री पर आधारित एक कैश-सचेत डेटा संरचना है जो कुशल स्ट्रिंग भंडारण और पुनर्प्राप्ति और आदेशित पुनरावृत्तियों की प्रस्तुत करती है। समय और स्थान दोनों के संबंध में प्रदर्शन है कैश-सचेत हैश तालिका के तुलनीय।[8][9]
पेट्रीसिया ट्राई मूलांक 2 (बाइनरी) ट्राई का एक विशेष प्रकार है, जिसमें प्रत्येक कुंजी के प्रत्येक बिट को स्पष्ट रूप से संग्रहीत करने के अतिरिक्त, नोड्स केवल पहले बिट की स्थिति को संग्रहीत करते है जो दो उप-वृक्षों को अलग करता है। ट्रैवर्सल के दौरान एल्गोरिदम खोज कुंजी के अनुक्रमित बिट की जांच करता है और उपयुक्त के रूप में बाएं या दाएं उप-पेड़ को चुनता है। पेट्रीसिया ट्राई की उल्लेखनीय विशेषताओं में यह सम्मलित है कि ट्राई को संग्रहीत प्रत्येक अद्वितीय कुंजी के लिए केवल एक नोड डालने की आवश्यकता होती है, जो पेट्रीसिया को मानक बाइनरी ट्राई की तुलना में अधिक कॉम्पैक्ट बनाता है। इसके अतिरिक्त, चूंकि वास्तविक कुंजियाँ अब स्पष्ट रूप से संग्रहीत नहीं है, इसलिए मिलान की पुष्टि करने के लिए अनुक्रमित रिकॉर्ड पर एक पूर्ण कुंजी तुलना करना आवश्यक है। इस संबंध में पेट्रीसिया हैश तालिका का उपयोग करके अनुक्रमण के साथ एक निश्चित समानता रखती है।[10] अनुकूली मूलांक वृक्ष एक मूलांक वृक्ष प्रकार है जो मूलांक वृक्ष में अनुकूली नोड आकार को एकीकृत करता है। सामान्य मूलांक वृक्षों का एक बड़ा दोष स्थान का उपयोग है, क्योंकि यह हर स्तर पर एक स्थिर नोड आकार का उपयोग करता है। मूलांक ट्री और एडाप्टिव मूलांक ट्री के बीच मुख्य अंतर चाइल्ड तत्वों की संख्या के आधार पर प्रत्येक नोड के लिए इसका परिवर्तनशील आकार है, जो नई प्रविष्टियाँ जोड़ते समय बढ़ता है। इसलिए, अनुकूली मूलांक वृक्ष अंतरिक्ष की गति को कम किए बिना उसके बेहतर उपयोग की ओर ले जाता है।[11][12][13] ऐसी स्थितियों में जहां माता-पिता डेटा सेट में एक वैध कुंजी का प्रतिनिधित्व करते है, केवल एक बच्चे वाले माता-पिता को अनुमति न देने के मानदंडों में ढील देना एक आम प्रथा है। मूलांक ट्री का यह संस्करण उस संस्करण की तुलना में उच्च स्थान दक्षता प्राप्त करता है जो केवल कम से कम दो बच्चों के साथ आंतरिक नोड्स की अनुमति देता है।[14]
यह भी देखें
- उपसर्ग वृक्ष (जिसे ट्राइ के नाम से भी जाना जाता है)
- नियतात्मक चक्रीय परिमित अवस्था ऑटोमेटन (डीएएफएसए)
- टर्नरी खोज प्रयास करता है
- हैश ट्राई
- नियतात्मक परिमित ऑटोमेटा
- जूडी सरणी
- खोज एल्गोरिथ्म
- विस्तार योग्य हैशिंग
- हैश ऐरे मैप किया गया ट्राई
- उपसर्ग हैश ट्री
- बर्स्टसॉर्ट
- लुलेआ एल्गोरिथ्म
- हफ़मैन कोडिंग
संदर्भ
- ↑ Morin, Patrick. "स्ट्रिंग्स के लिए डेटा संरचनाएँ" (PDF). Retrieved 15 April 2012.
- ↑ "rtfree(9)". www.freebsd.org. Retrieved 2016-10-23.
- ↑ The Regents of the University of California (1993). "/sys/net/radix.c". BSD Cross Reference. NetBSD. Retrieved 2019-07-25.
Routines to build and maintain radix trees for routing lookups.
- ↑ "Lockless, atomic and generic Radix/Patricia trees". NetBSD. 2011.
- ↑ Knizhnik, Konstantin. "Patricia Tries: A Better Index For Prefix Searches", Dr. Dobb's Journal, June, 2008.
- ↑ Morrison, Donald R. PATRICIA -- Practical Algorithm to Retrieve Information Coded in Alphanumeric
- ↑ G. Gwehenberger, Anwendung einer binären Verweiskettenmethode beim Aufbau von Listen. Elektronische Rechenanlagen 10 (1968), pp. 223–226
- ↑ Askitis, Nikolas; Sinha, Ranjan (2007). HAT-trie: A Cache-conscious Trie-based Data Structure for Strings. pp. 97–105. ISBN 1-920682-43-0.
{{cite book}}:|journal=ignored (help) - ↑ Askitis, Nikolas; Sinha, Ranjan (October 2010). "Engineering scalable, cache and space efficient tries for strings". The VLDB Journal. 19 (5): 633–660. doi:10.1007/s00778-010-0183-9.
- ↑ Morrison, Donald R. PATRICIA -- Practical Algorithm to Retrieve Information Coded in Alphanumeric
- ↑ Kemper, Alfons; Eickler, André (2013). Datenbanksysteme, Eine Einführung. Vol. 9. pp. 604–605. ISBN 978-3-486-72139-3.
- ↑ "armon/libart: Adaptive Radix Trees implemented in C". GitHub. Retrieved 17 September 2014.
- ↑ Viktor Leis; et al. (2013). "The adaptive radix tree: ARTful indexing for main-memory databases". IEEE 29th International Conference on Data Engineering (ICDE): 38–49. doi:10.1109/ICDE.2013.6544812.
- ↑ Can a node of Radix tree which represents a valid key have one child?
बाहरी संबंध
- Algorithms and Data Structures Research & Reference Material: PATRICIA, by Lloyd Allison, Monash University
- Patricia Tree, NIST Dictionary of Algorithms and Data Structures
- Crit-bit trees, by Daniel J. Bernstein
- Radix Tree API in the Linux Kernel, by Jonathan Corbet
- Kart (key alteration radix tree), by Paul Jarc
- The Adaptive Radix Tree: ARTful Indexing for Main-Memory Databases, by Viktor Leis, Alfons Kemper, Thomas Neumann, Technical University of Munich
कार्यान्वयन
- FreeBSD कार्यान्वयन, पेजिंग, अग्रेषण और अन्य चीजों के लिए उपयोग किया जाता है।
- लिनक्स कर्नेल कार्यान्वयन, अन्य चीजों के अतिरिक्त पेज कैश के लिए उपयोग किया जाता है।
- GNU C++ मानक लाइब्रेरी में एक त्रि कार्यान्वयन है
- समवर्ती मूलांक ट्री का जावा कार्यान्वयन, नियाल गैलाघेर द्वारा
- C# मूलांक ट्री का कार्यान्वयन
- प्रैक्टिकल एल्गोरिथम टेम्प्लेट लाइब्रेरी, PATRICIA पर एक C++ लाइब्रेरी (VC++ >=2003, GCC G++ 3.x), रोमन एस. क्लुजकोव द्वारा
- पेट्रीसिया ट्राई C++ टेम्पलेट क्लास कार्यान्वयन, राडू ग्रुइयन द्वारा
- हास्केल मानक पुस्तकालय कार्यान्वयन बड़े-एंडियन पेट्रीसिया पेड़ों पर आधारित। वेब-ब्राउज़ करने योग्य स्रोत कोड।
- जावा में पेट्रीसिया ट्राई कार्यान्वयन, रोजर काप्सी और सैम बर्लिन द्वारा
- क्रिट-बिट पेड़ डैनियल जे. बर्नस्टीन द्वारा सी कोड से लिया गया
- सी में पेट्रीसिया ट्राई कार्यान्वयन, libcprops में
- पेट्रीसिया ट्रीज़: पूर्णांकों पर कुशल सेट और मानचित्र :fr:ऑब्जेक्टिव कैमल, जीन-क्रिस्टोफ़ फ़िलियाट्रे द्वारा
- मूलांक डीबी (पेट्रीसिया ट्राई) सी में कार्यान्वयन, जी. बी. वर्सियानी द्वारा
- लिबार्ट - सी में लागू अनुकूली मूलांक ट्री, अन्य योगदानकर्ताओं के साथ आर्मोन डैडगर द्वारा (ओपन सोर्स, बीएसडी 3-क्लॉज लाइसेंस)
- क्रिट-बिट ट्री का निम कार्यान्वयन
- rax, साल्वाटोर सैनफिलिपो (REDIS के निर्माता) द्वारा ANSI C में एक मूलांक ट्री कार्यान्वयन
श्रेणी:पेड़ (डेटा संरचनाएं) श्रेणी:स्ट्रिंग डेटा संरचनाएँ